Confluence Connector Documentation
If you have already set up a connector, skip to How to Use the Confluence Connector.
Connect your Confluence to Abacus.AI
To enable the integration of Confluence with Abacus.AI, you need to generate an API token in Confluence for authentication purposes.
-
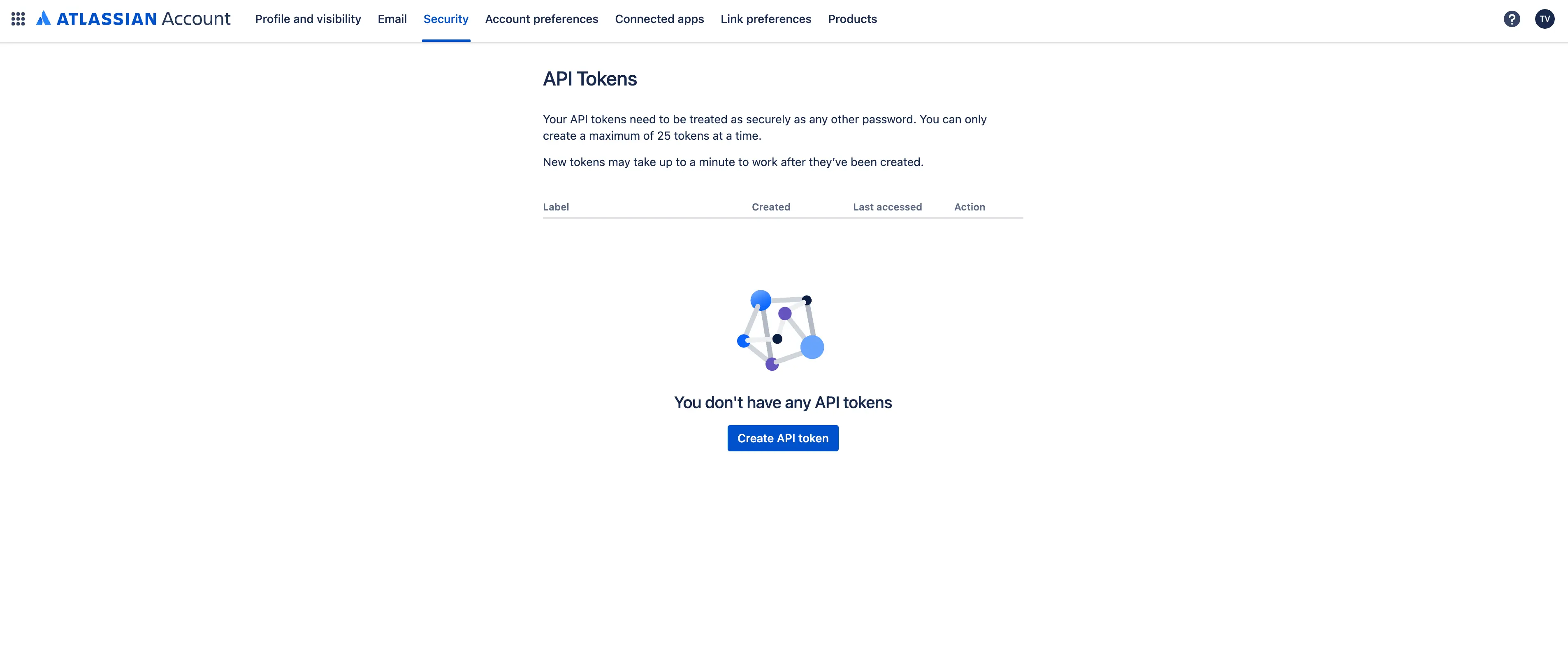
Visit the Atlassian API token creation page at https://id.atlassian.com/manage-profile/security/api-tokens and generate a new API token. Remember to copy the token after creation.
-
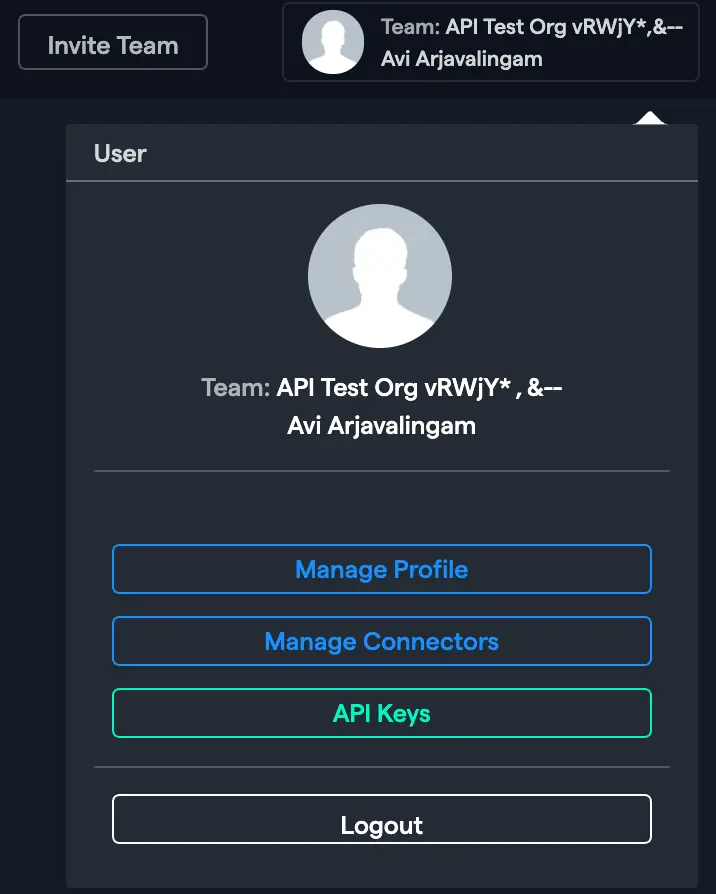
In the Abacus.AI web interface, click on your profile picture in the top right corner.

-
From the dropdown menu, select "Manage Connectors".
-
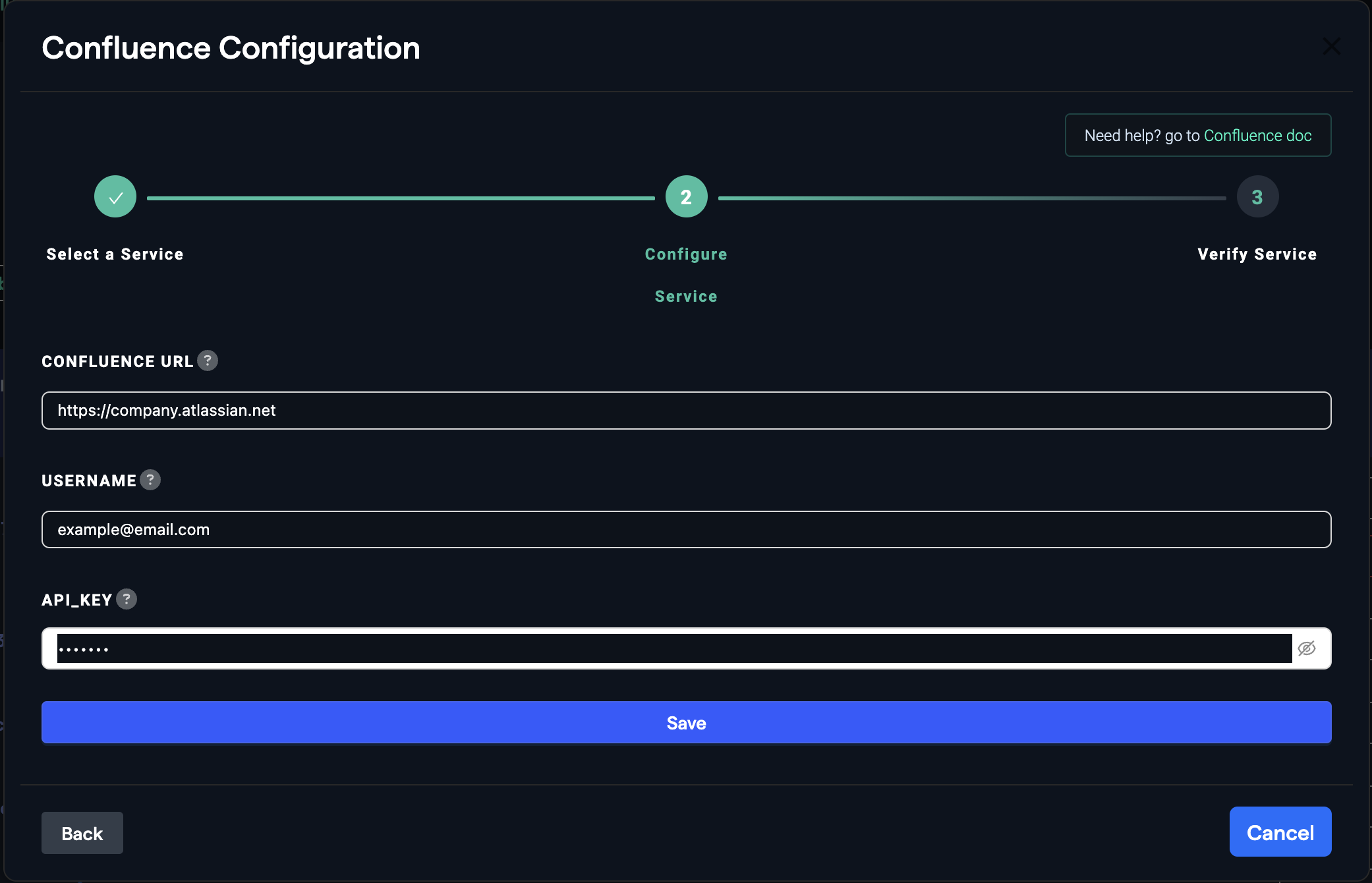
Click on "Add New Connector", choose "Confluence" from the list, and enter the required information including the API token you generated earlier. Click "Save" to finish setting up the connector.
How to Use the Confluence Connector
Once the Confluence connector is set up, you can fetch data to train models in Abacus.AI.
-
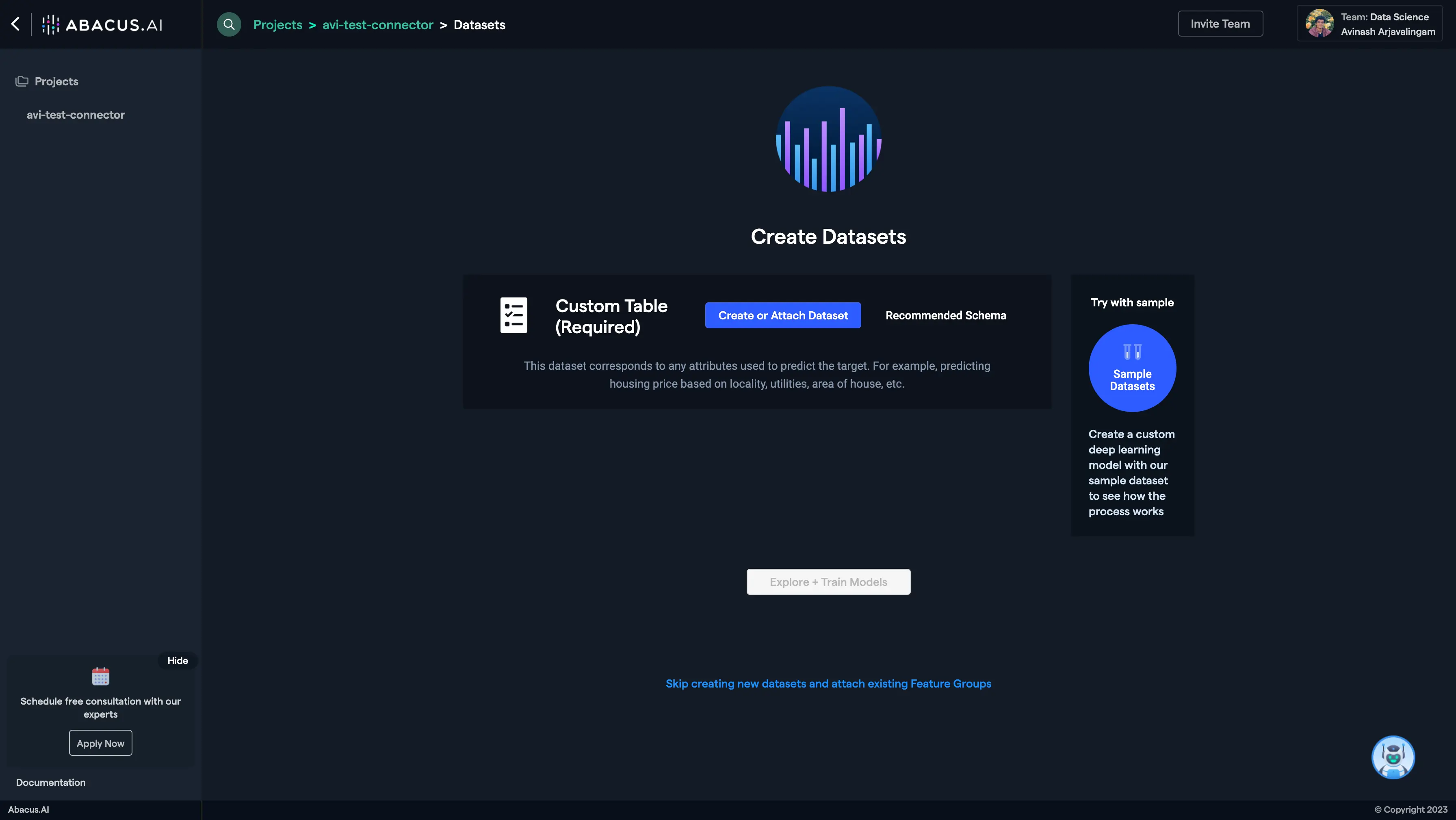
Create a new project and select the use case, then go to the "Datasets" tab and click "Create Dataset".
-
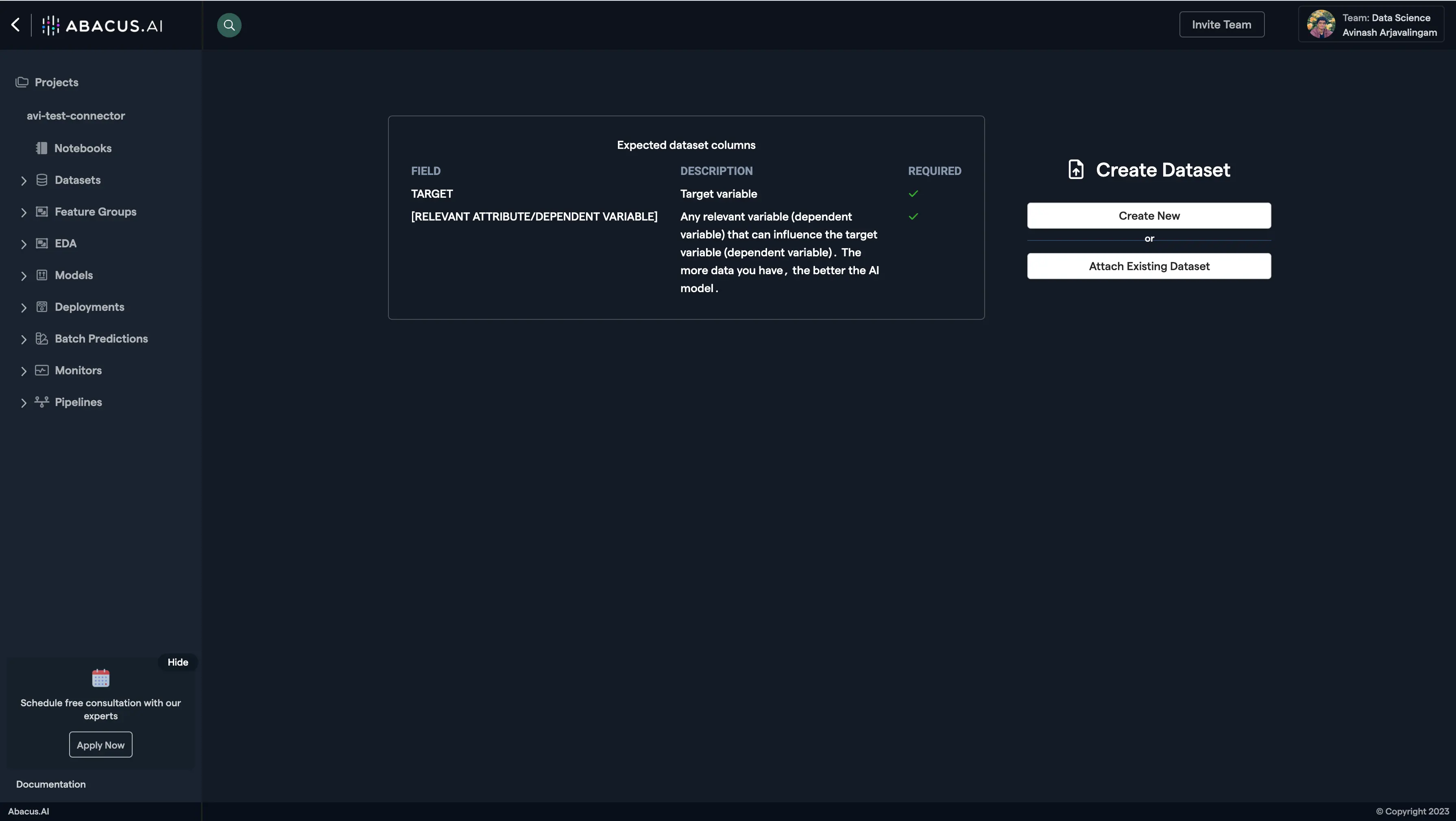
Click on "Create New".
-
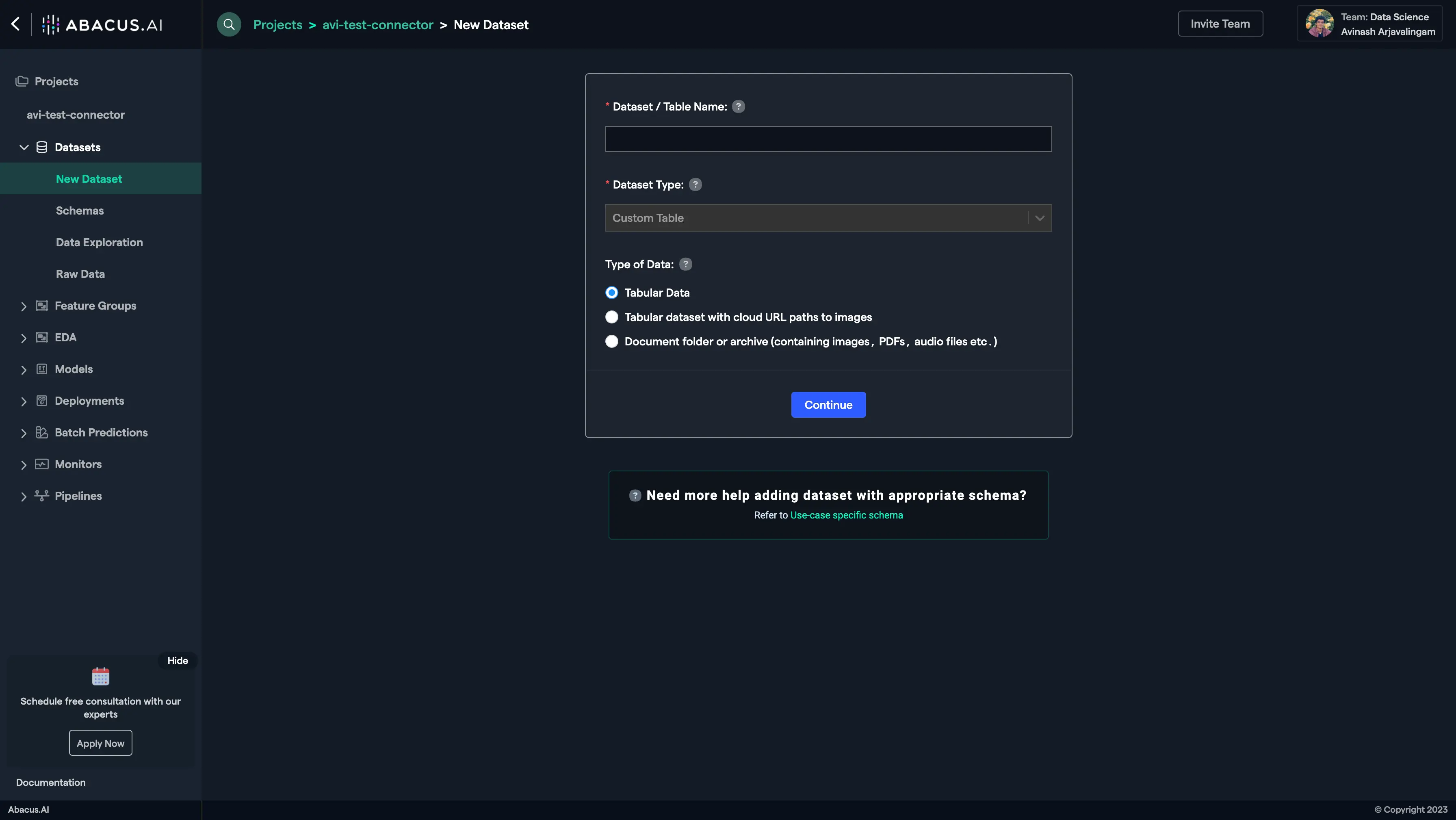
Name the dataset, select the data type 'List of documents', and click "Continue".
-
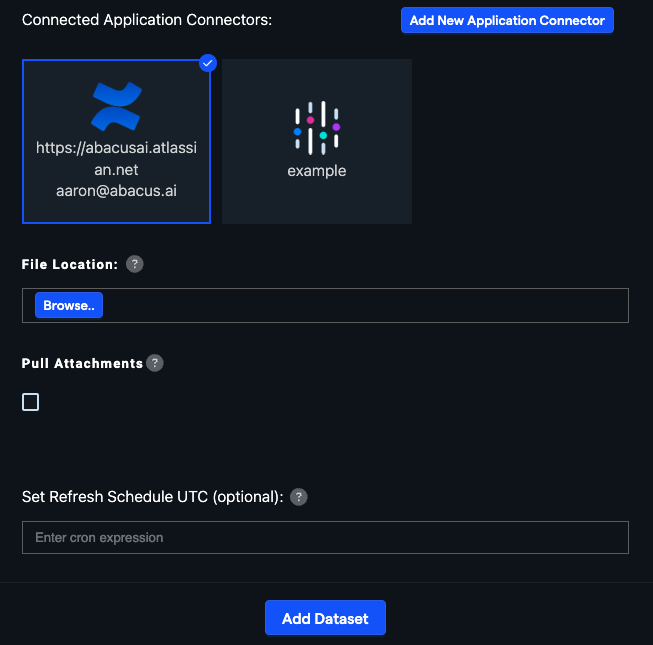
Choose "Read from External Service" and select your Confluence connector under "Connected Application Connectors".
-
Under "File location", click the "Browse" button. This will open an application browser where you can select the Confluence space(s) you want to pull data from. The multi-space functionality allows you to select multiple spaces at once.
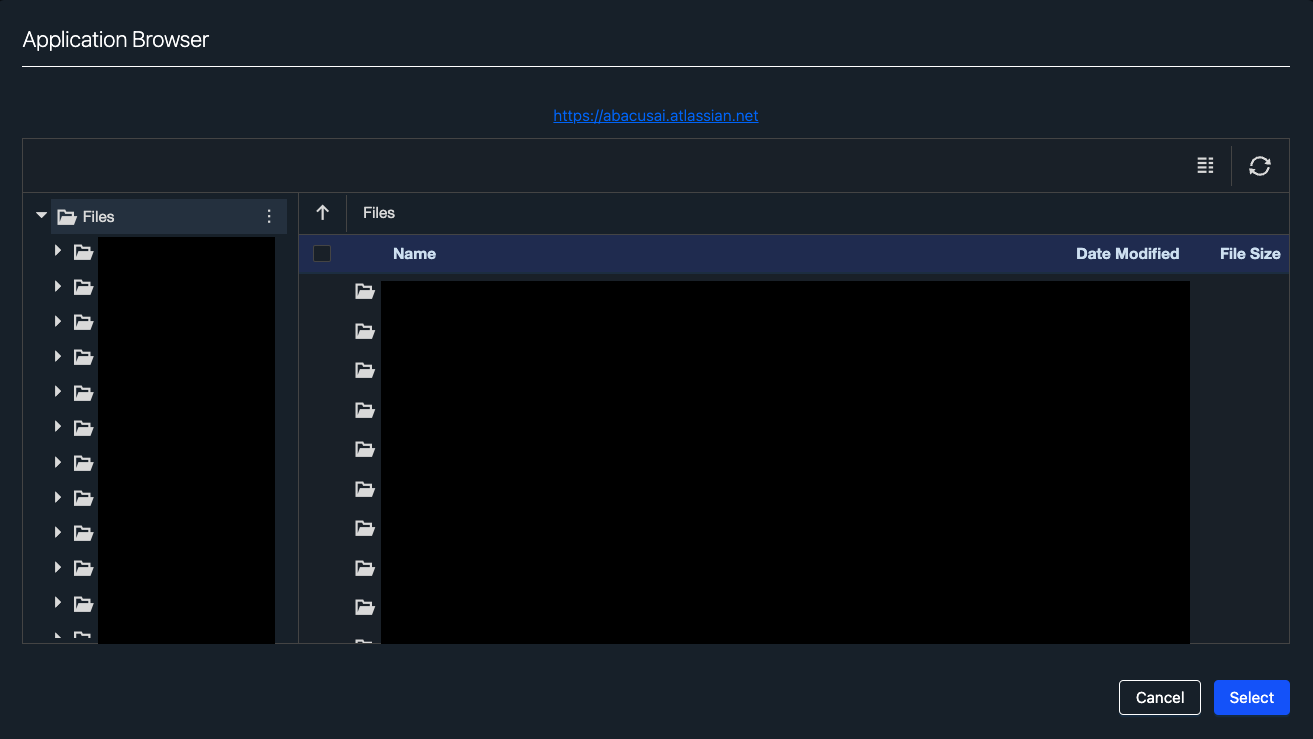
-
If you want to include attachments in your dataset, check the "Pull Attachments" option.
-
Select any additional document processing configuration desired under "Advanced Options."
-
After the dataset is uploaded, configure the schema mapping and proceed to train models with the data.