Feature Group Operations
Learning Objectives
The learning objectives of this are:
- To learn what feature group operations are
- How to access feature group operations
- How to use a crawler feature group operation
Introduction
Abacus has multiple feature group operations that can be accessed using the “Actions” button.
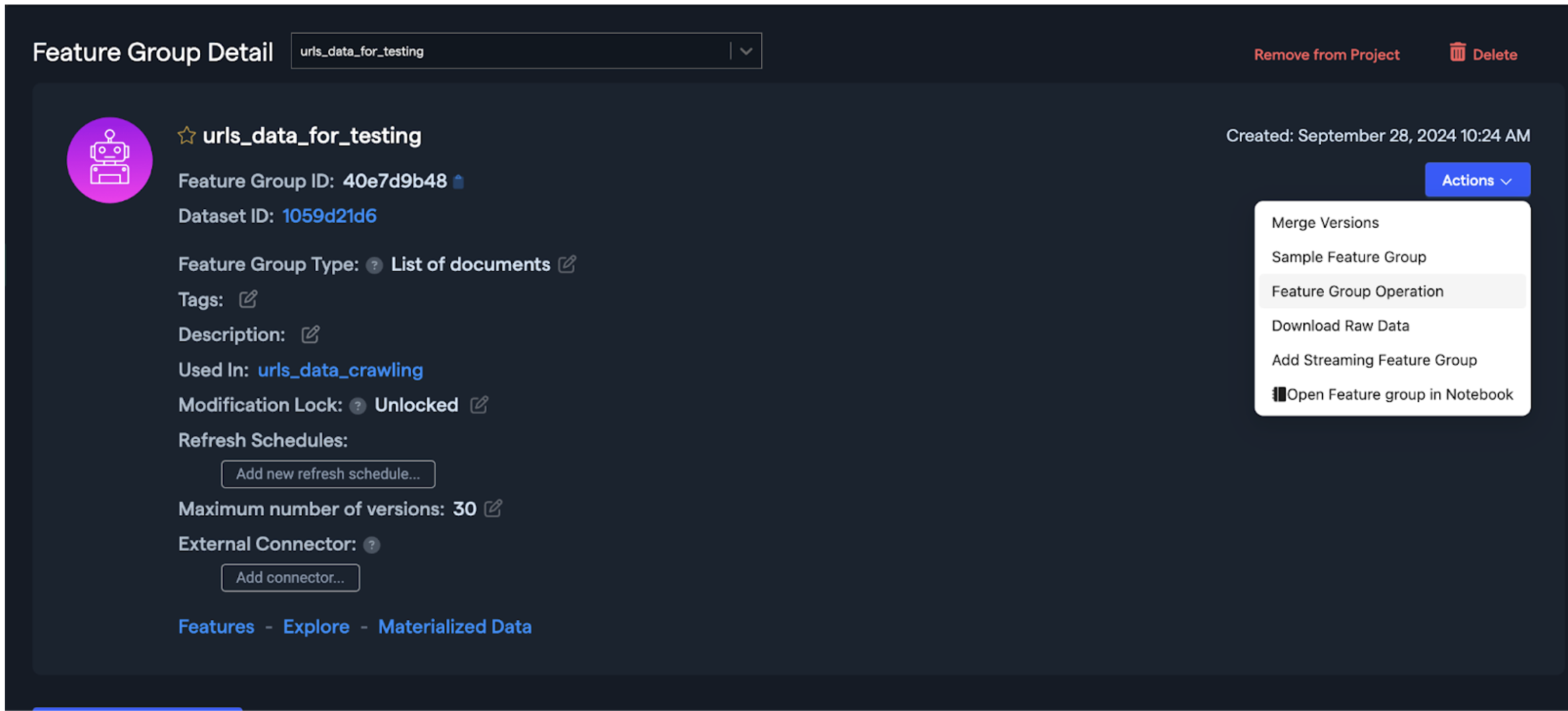
Instead of having to write API code or SQL code to execute a task, you can use one of the predefined tasks that exist in the actions button.
Example tasks are:
- Sample Feature Group
- Create a sample of the existing feature group either randomly or by using stratified sampling with sampling keys.
- Merge Versions
- Merge versions of a feature group. It would work as if you concatenated multiple dataframes together.
- Feature Group Operation
- Transpose (unpivot) operation.
- Markdown: Convert the input column to Markdown.
- Crawler: Crawl web pages and extract information.
- Extract Document Data: Extracts data like text and tokens from documents.
- Data Generation: Generate synthetic data by prompting an LLM with instructions and example (prompt, completion) pairs.
The feature group operations and tasks will create a new feature group that will be referencing the original feature group.
Creating a Web Crawler
As an example, let’s see how we could create a web crawler using a feature group operation.
The steps are:
- Navigate to the “Detail” page of a particular feature group.
-
Click on “Actions” —> “Feature Group Operation”
-
Choose the “Crawler” feature group operation.
Here is how your dataset should look like:
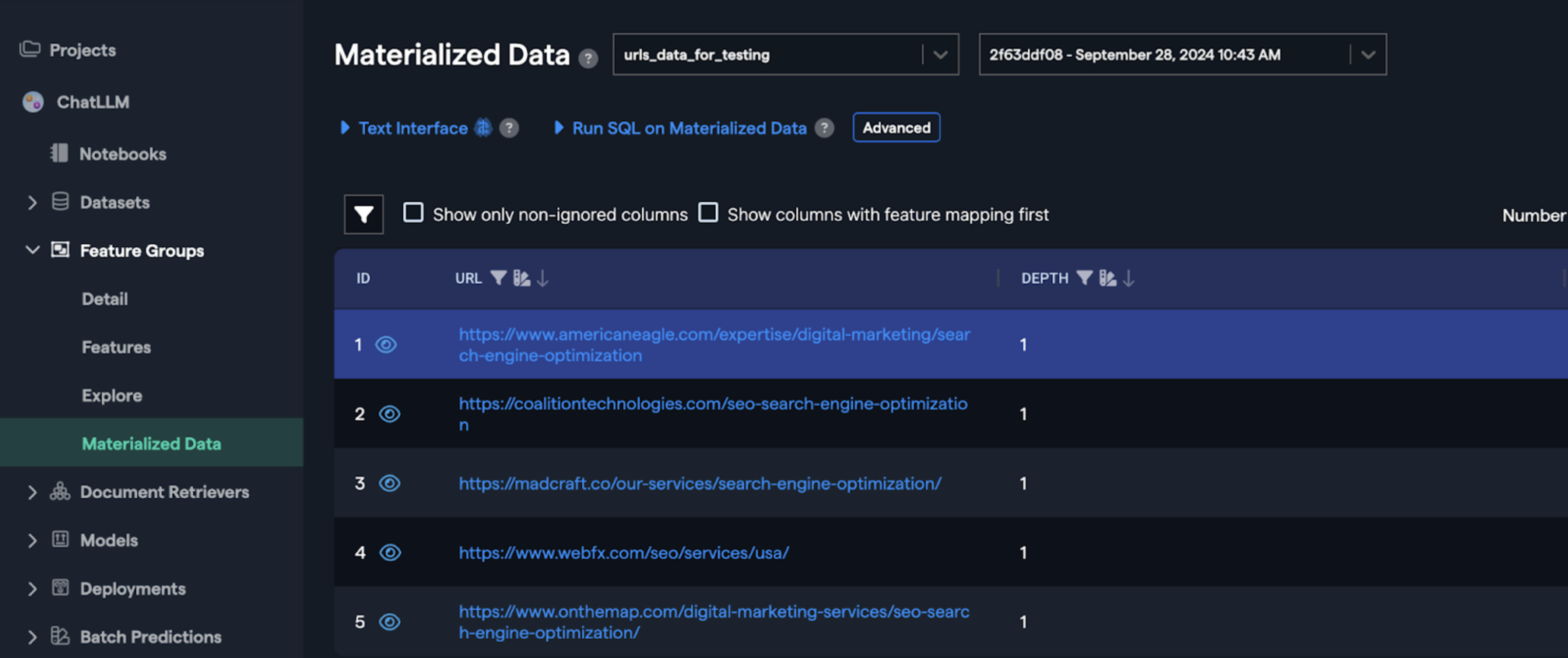
There are two columns here:
- URL: This is the URL that the crawler will extract data from
- Depth: Whether we will extract data only from the given URL or from URL’s that are within that URL as well.
There are also multiple advanced options that might help crawl websites that require a user agent. Please note that we will honor the settings within the `robots.txt` file and won’t crawl websites that don’t allow for web crawling.