The research team at Abacus.AI makes fundamental contributions to the field of AI, with wide-ranging impact across both foundational and applied topics for the betterment of our customers and science.
We focus on open LLMs, fine-tuning, large agentic loops, and self-improving loops — building open models and agentic systems that continuously get better at solving real-world tasks.
The team has an impressive list of publications in top-tier conferences.
Read on for detailed explanations of our active areas of research and product development, which are focused on solving hard problems faced by today's organizations.
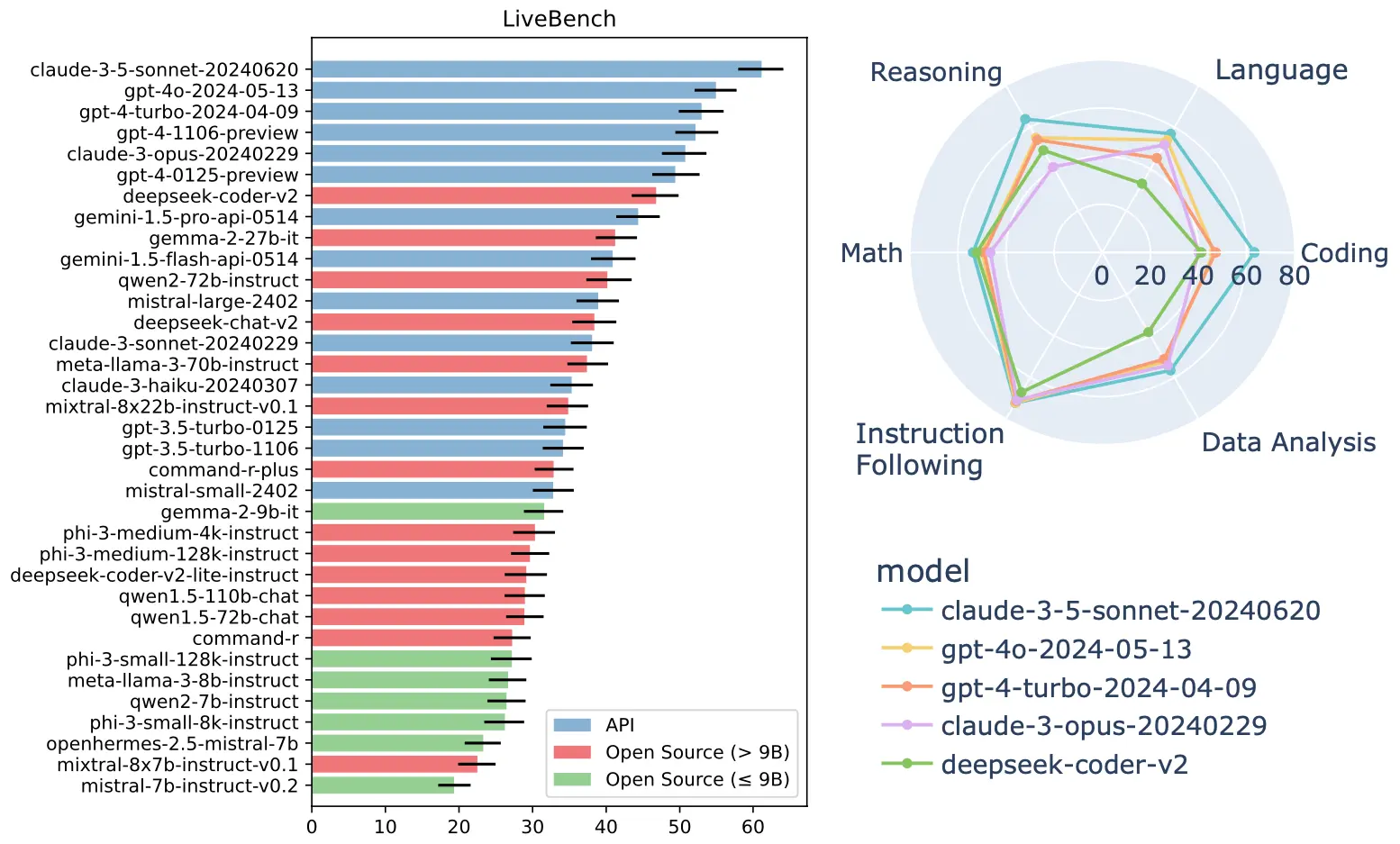
We are leaders in open-source Gen-AI and have introduced a contamination-free benchmark,
livebench.ai,
regarded industry-wide as the go-to benchmark for evaluating LLMs for real-world use. In addition, we have released several gen-AI fine tunes, including Dracarys, Smaug, and Giraffe. Read more about our
open-source contributions here.
General Purpose AI Agents - Building Reliable LLM Agents
We're developing agentic systems that perform reliably on real world tasks—creating presentations, deployable websites, and research reports—not just benchmarks. To achieve this, we've built a technical framework that treats the agent as a full-stack system spanning planning, retrieval, reasoning, tool execution, and verification, and evaluates it end-to-end under realistic conditions. By optimizing against outcome-quality rather than proxy scores, we generate improvements that show up in production.
Our quality suites are derived from actual usage of our platform. Tasks are constructed from the kinds of requests customers make, such as producing a board-ready deck from a short brief and several PDFs, generating a responsive microsite from a design spec, or compiling a literature review with citations and a clean bibliography. Inputs are intentionally messy and specifications can be incomplete, and tools are exercised under realistic latencies and failure modes. We use rubric-driven evaluators specialized to the deliverable type so that the grader's criteria reflect structure, coverage, and correctness of the artifacts.
We evaluate the system end to end. Agents must plan multi-step workflows, decompose and recombine subtasks, and coordinate subagents for synthesis, code generation, retrieval, and verification. Tools are treated as typed, stateful components with explicit contracts; we measure schema conformance, idempotency, retries and timeouts, and targeted recovery when operations fail. Because we measure model behavior and tool fidelity together, we can pinpoint whether bottlenecks arise from prompting, routing policies, or a specific adapter's implementation.
Inside the agent, we optimize where it matters most. Subtasks like planning, long-form synthesis, code generation, summarization, and factual verification are routed to different foundation models chosen along quality, latency, and cost frontiers. Context is managed with strict token budgeting, hierarchical summaries, and section-aware retrieval so that subagents exchange compact, typed state—plans, constraints, and evidence sets—rather than raw text dumps. Prompts are versioned per task family and use structured output constraints with lightweight scratchpads to preserve reasoning reliability without unnecessary verbosity.
We treat agent development like continuous integration. Every change to prompts, routing, tools, or policies runs through the quality suites with statistical guardrails to prevent regressions. We maintain cost–latency–quality frontiers for common workflows and tune policies to meet practical SLAs, such as bounding p95 latency while maintaining a minimum quality threshold and reasonable cost.
The outcome of this approach is straightforward: higher completion rates on real tasks, fewer unnecessary retries thanks to targeted repair, predictable latency and cost through subtask routing and selective verification, and quality gains that generalize across workflows because they address systemic failure modes like state handoff and tool reliability. Overall, this gives us a robust process for improving agents over time and for leveraging the latest foundation models effectively.
At Abacus.AI, we actively research how large language models can be adapted for client's needs, particularly for in-demand industry applications such as chat bots, search, and question answering. We offer these solutions by starting with state-of-the-art large language models, and then performing a custom fine-tuning procedure in order to maximize the accuracy of the desired task. We are able to adapt LLMs to customer needs by learning from their knowledge base of internal documents, customer feedback, code, etc. and deploying solutions into production.
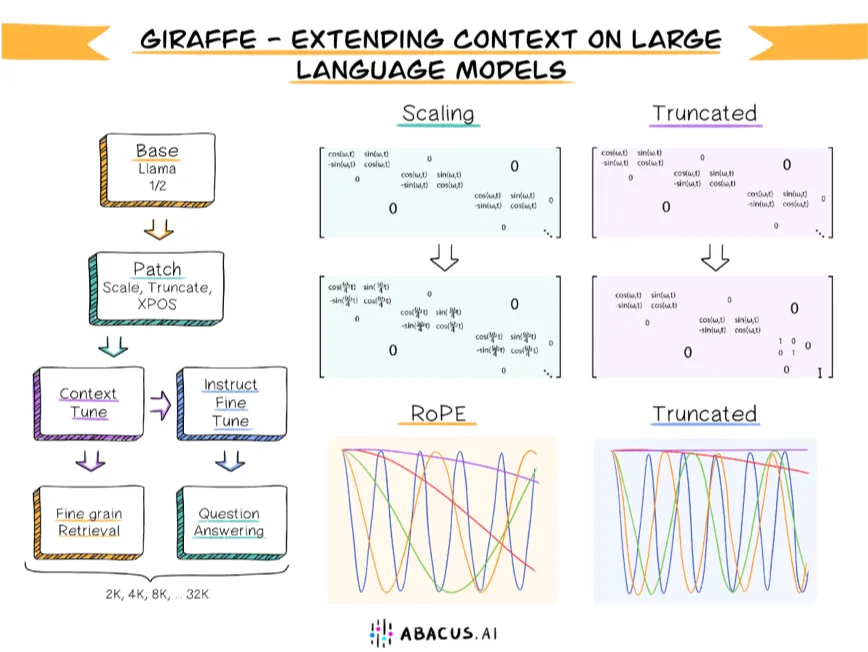
We are deeply committed to open-source research in LLMs and have worked actively on collaboratively building solutions in the open. One challenge that the community faces is cheaply building LLMs which can read and reason about longer input texts. This concept of context extension is a core area of research for Abacus.AI and one where we've proven advanced techniques in both algorithmically increasing context length and expansive datasets to measure progress.
Code Generation
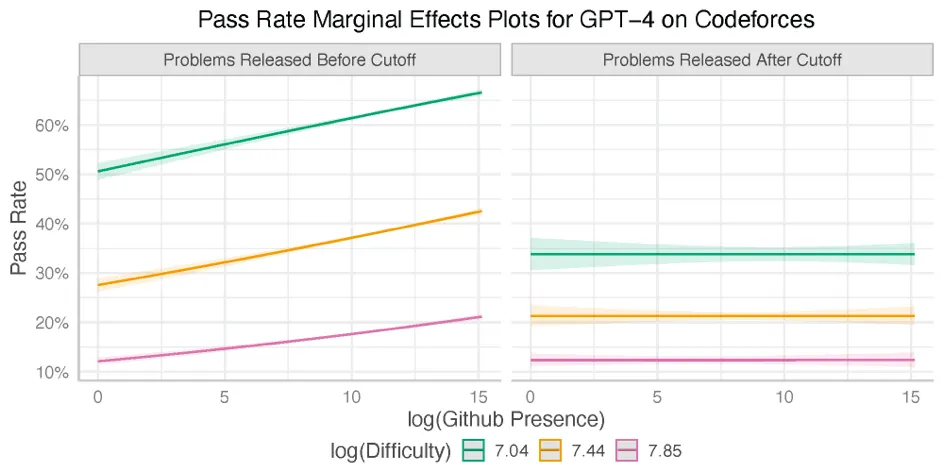
In recent years, researchers have made remarkable advances in generative language modeling tasks, with present generative AI systems capable of writing syntactically and functionally correct code. With the increased capabilities of generative AI systems, it is natural to ask questions about the ability of generative systems to write executable code by data scientists and organizations. We are researching the correct ways to build and deploy these systems, with a particular focus on how to evaluate code generating systems.
At Abacus.AI, we believe that the next frontier for language models is in AI-assisted data science. We are developing generative models that can interpret and then execute commands given in natural language (such as, "Train a 10-layer MLP and plot the validation accuracy over time"). By fine-tuning the model on our own Abacus.AI APIs, the language model allows anyone to easily use Abacus.AI's platform to perform exploratory data analysis, visualize data, and train powerful machine learning models.
Time-Series Forecasting
Time-series forecasting is a ubiquitous problem in the industry, used for problems such as forecasting inventory demand and predicting stock prices. While statistical approaches such as ARIMA and Prophet are widely used, deep learning models such as transformers are getting increasingly more popular. However, many high-impact forecasting problems are either low-data, or low signal-to-noise ratio, and many forecastable datasets have standard attributes that carry over to other datasets.
With this intuition in mind, Abacus.AI has developed a radically new approach to time-series forecasting. Inspired by recent innovations in meta-learning and Bayesian inference on tabular data, we have designed the world's first foundation model for time-series forecasting. To achieve this, we pretrain a transformer on a mix of real-world and synthetic datasets, across a variety of different forecasting tasks, resulting in a state-of-the-art forecasting model that can run inference on a new dataset in less than a second.
Manley Roberts, Himanshu Thakur, Christine Herlihy, Colin White, Samuel Dooley
Under Submission
Deep recommender systems
Deep Recommender Systems
Recommender systems are used heavily across e-commerce, social media, and entertainment companies such as Amazon, YouTube, and Netflix. While early approaches included k-nearest-neighbor or matrix factorization, deep learning is becoming the dominant paradigm in recommender systems due to the scale and complexity of modern recommender system datasets. At Abacus.AI, we have developed multiple deep learning approaches to recommender systems for use cases such as session-based item recommendation, personalized search query results, and personalized related item recommendations. Our deep learning models are based on state-of-the-art techniques such as two-tower models, which use separate embedding layers for the user history as well as the items, and then makes recommendations based on cosine similarity. We also use recurrent neural networks such as long short-term memory (LSTM) to capture temporal relationships in each user's history.
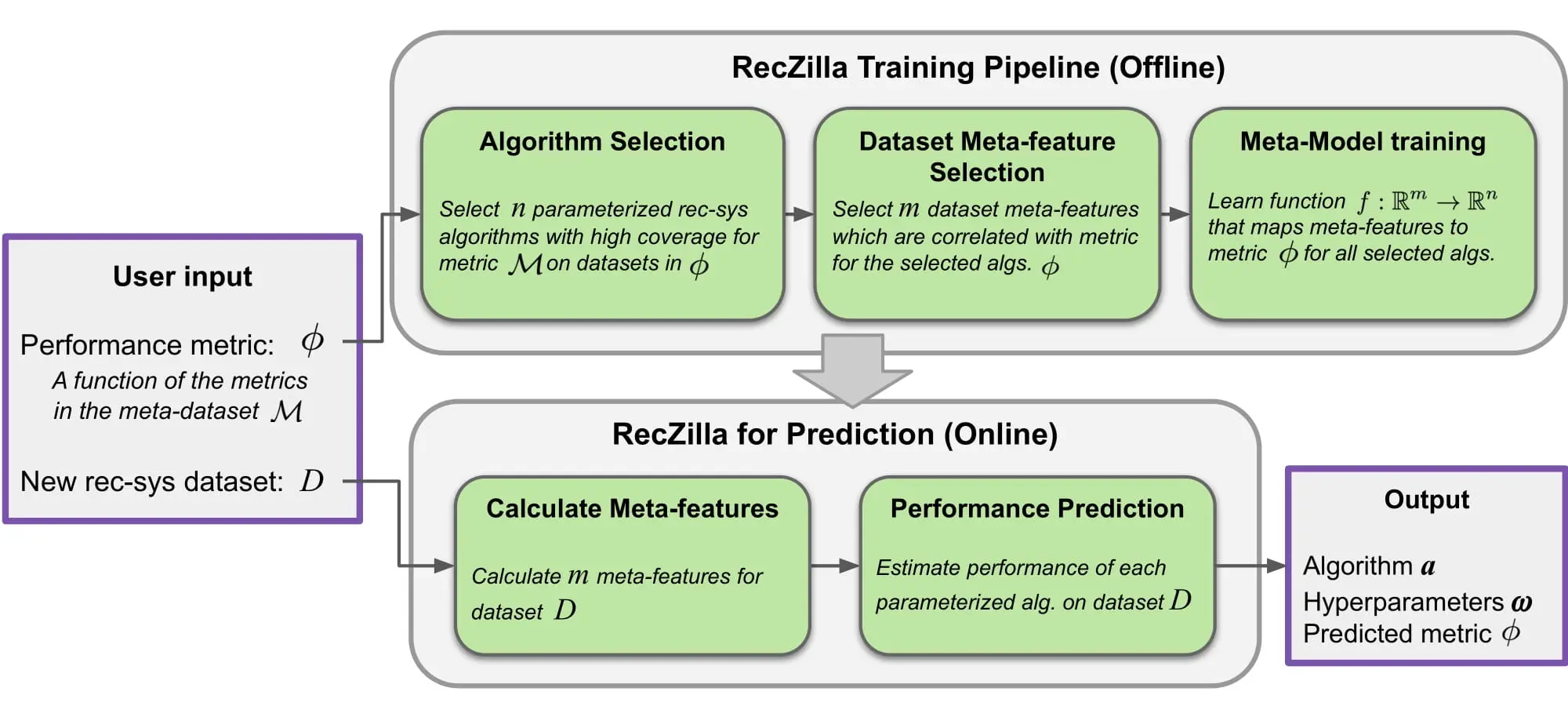
Meta-Learning to Ensure Performance
In order to ensure our deep learning models achieve the highest possible performance, we use meta-learning to rapidly find the best algorithm and hyperparameters for new datasets. For more details, see our published research paper below. Our system also compares the best approaches to well-tuned baselines such as P3Alpha, RP3Beta, SLIM-Elastic-Net, and Co-Clustering, to make sure that we achieve the best possible performance.
Vector Store
The size of the datasets in large retail and e-commerce companies can reach millions of items and billions of total interactions, and deployed models often face millions of requests per day. In order to keep the latency of each request low, Abacus.AI uses our custom-designed, state-of-the-art vector store. Powered by GPUs, our vector store is able to scale up to 10,000+ queries per second, with less than 20ms latency per request.
Duncan McElfresh, Sujay Khandagale, Jonathan Valverde, John Dickerson, Colin White
Workshop at AutoML-Conf
Training with Less Data
While organizations today might have large amounts of data, their datasets tend to be noisy, incomplete and imbalanced. This results in data scientists and engineers spending most of their precious time pre-processing, cleaning, and featurizing the data. These efforts are often insufficient, and deep learning techniques routinely fail on sparse datasets. Organizations are then forced to use classical machine learning techniques that require enormous amounts of manual feature engineering. At Abacus.AI, we are actively pursuing the following research areas that will enable training on less data.
Meta-Learning
Deep learning models typically require training with a large number of training samples. On the other hand, humans learn concepts and skills much more quickly and efficiently. We only need a few examples to tell lions apart from cats. Meta-learning is a sub-field of machine learning that aims to teach models how to learn. We hope to build on the work outlined by Model-Agnostic Meta-Learning (MAML) and first-order Meta-Learning Algorithms. The MAML algorithm provides a good initialization of a model's parameters to achieve an optimal fast learning on a new task with only a small number of gradient steps while avoiding overfitting that may happen when using a small dataset. Our service uses principles of meta-learning to create robust models even when you have a small number of training examples.
Generative Models for Dataset Augmentation
Dataset augmentation is a technique to synthetically expand a training dataset by applying a wide array of domain-specific transformations. This is a particularly useful tool for small datasets, and it is even shown to be effective on large datasets like Imagenet. While it is a standard tool used in training supervised deep learning models, it requires extensive domain knowledge, and the transformations must be designed and tested carefully. Over the last 2 years, Generative Adversarial Networks (GANs) have been used successfully for dataset augmentation in various domains including computer vision, anomaly detection, and forecasting. The use of GANs makes dataset augmentation possible even with little or no domain-specific knowledge. Fundamentally, GANs learn how to produce data from a dataset that is indistinguishable from the original data. However, there are some practical issues with using GANs, and training a GAN is notoriously difficult. GANs have been a very active area of research, and several new types of GANs including Wasserstein GANs and MMD GANs address some of these issues. Recently, there has also been some work on domain-agnostic GAN implementation for dataset augmentation. At Abacus.AI, we are innovating on the state-of-the-art GAN algorithms that can perform well on noisy and incomplete datasets. We have innovated on Data Augmentation Generative Adversarial Networks to create synthetic datasets that can be combined with original datasets to create more robust models. The demo on our homepage is based on GANs. Check out this blog post to see how it works.
Combining Neural Nets with Logic Rules/Specifications
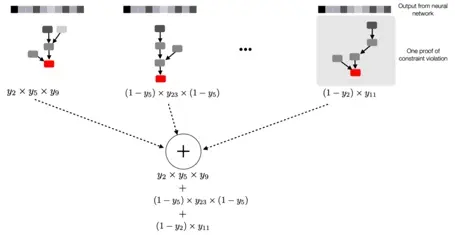
The cognitive process of human beings indicates that people learn not only from concrete examples (as deep neural nets do) but also from different forms of general knowledge and rich experiences. It's difficult to encode human intention to guide the models to capture desired patterns. In fact, most enterprise systems today are rule-based. Experts have encoded rules based on tribal knowledge from their domains. ML models that are built to replace these rule-based systems often struggle to beat them on accuracy, especially when there is sparse data. At Abacus.AI, we are working on preserving expert knowledge by developing hybrid systems that combine logic rules with neural nets. While there is some recent research in this area, including a recent paper by DeepMind that lays the groundwork for a general-purpose, constraint-driven AI, it is still nascent. Most research papers don't address building these hybrid models at scale or incorporating multiple rules into the models. Abacus.AI is working on a service that allows developers and data scientists to specify multiple knowledge rules along with training data to develop accurate models. For example, there may be a rule that 'dog owners tend to like buying dog toys' in a recommender system or a constraint that a learned dynamic system must be consistent with physical law. Our publication in this area combines first-order logic constraints with conventional supervised learning.
Transfer Learning
Transfer learning is a machine learning technique that allows us to reuse policies from one domain or dataset on a related domain or dataset. By using transfer learning, we enable organizations to train models in a simulated environment and apply them in the real world. State-of-the-art language and vision modeling techniques typically pre-train on a large dataset, then either use fine-tuning or transfer learning to train a custom model on the target dataset. Abacus.AI packages and extends the state-of-the-art transfer learning techniques that result in the most performant models. As part of our service, we plan to package pre-trained language and vision models. We'll also make it easy to fine-tune those models or apply transfer learning to adapt them for a custom task.
NeurIPS Workshop on Knowledge Representation to ML
AI-Assisted ML
Deep learning has seen great success across a wide variety of domains. The best neural architectures are often carefully constructed by seasoned deep learning experts in each domain. For example, years of experimentation have shown how to arrange bidirectional transformers to work well for language tasks and dilated separable convolutions for image tasks. A relatively new sub-field of deep-learning deals with automated machine learning, or as we prefer to call it: AI-assisted machine learning. The fundamental idea is that AI will create a first pass of the deep-learning model given a use-case or a dataset. Developers/data scientists can then either use that model directly or fine-tune. We are conducting cutting-edge research in the main pillars of AI-Assisted ML: hyperparameter optimization (HPO) and neural architecture search (NAS).
Hyperparameter optimization
When developing a deep learning model, there are many knobs and dials to tune that depend on the specific task and dataset at hand. For example, setting the learning rate too high can prevent the algorithm from converging. Setting the learning rate too low can cause the algorithm to get stuck at a local minimum. There are countless other hyperparameters such as the number of epochs, batch size, momentum, regularization, shape, and size of the neural network. These hyperparameters are all dependent on each other and interact in intricate ways, so finding the best hyperparameters for a given dataset is an extremely difficult and highly nonconvex optimization problem.
Randomly testing different sets of hyperparameters may eventually find a decent solution but could take years of computation time. Efficiently tuning deep learning hyperparameters is an active area of research. Five years ago, the best algorithms weren't much better than random search. Now algorithms are capable of orders of magnitude speedups. At Abacus.AI, we use state-of-the-art HPO while training all our models.
Neural Architecture Search
Neural architecture search (NAS) is a rapidly developing area of research in which the process of choosing the best architecture is automated.
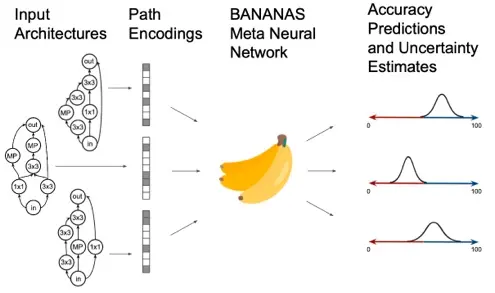
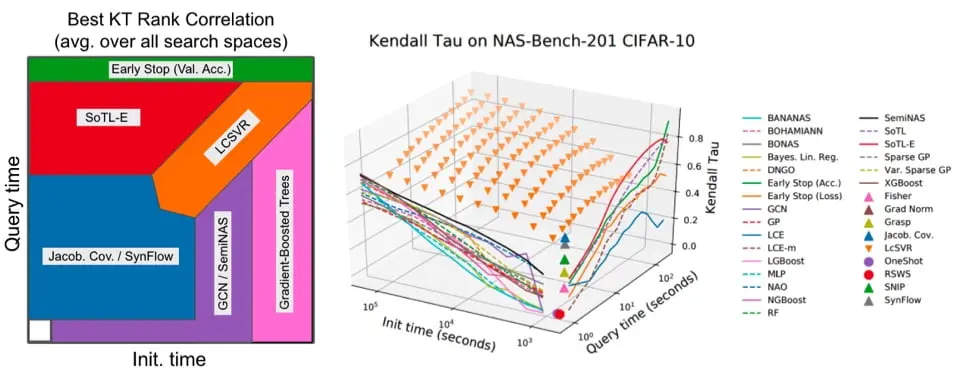
At Abacus.AI, we are using NAS to both fine-tune proven deep network paradigms, and learn novel architectures for new domains. Our goal is to empower data scientists and developers to create custom, production-grade models in days, not months. See this blog post to read about our method, BANANAS, which combines Bayesian optimization with neural predictors to achieve state-of-the-art performance. Since making our code open-source, dozens of developers have forked our repository, and two independentresearch groups have confirmed that it achieves state-of-the-art performance on NAS-Bench-101. BANANAS has even been cited in survey papers on NAS.
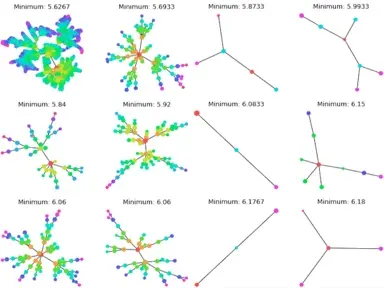
We are also actively conducting fundamental research on the theory of NAS. Recently, we studied local search for NAS - a simple yet effective approach. We showed experimentally that local search gives state-of-the-art performance on smaller benchmark NAS search spaces, but performs worse than random search on extremely large search spaces. Motivated by this stark contrast, we gave a complete theoretical characterization of local search. Our theoretical results confirm that local search performs well on smaller search spaces and when the search space exhibits locality.
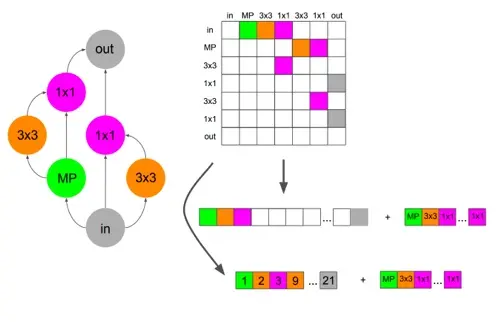
Finally, we are conducting formal studies on the building blocks of NAS, including the architecture encoding. In most NAS algorithms, the neural architectures must be passed as input to the algorithm using some encoding. For example, we might encode the neural architectures using an adjacency matrix. Our recent work shows that this encoding can have a substantial impact on the final result of the NAS algorithm. We conduct a set of experiments with eight different encodings with various NAS algorithms. Our results lay out recommendations for the best encodings to use in different settings within NAS.
Colin White, Arber Zela, Binxin Ru, Yang Liu, Frank Hutter
Selected as a contributed talk | ICLR Workshop on Neural Architecture Search
Bias and Explainability in Neural Nets
Bias is one of the most important issues in machine learning today. Deep learning models are being deployed in high-stakes scenarios today more than ever, and most of these models are found to exhibit prejudices. For example, the New York Times reported that the majority of facial recognition apps used by law enforcement agencies exhibit bias. They cited a study concluding that facial recognition technology is ten times more likely to falsely identify people of color, women and older people.
There has been considerable research in mitigating these biases, with dozens of definitions of bias and algorithms to decrease the level of bias. The majority of fair algorithms are in-processing algorithms, which take as input a training dataset and then train a new, fairer model from scratch. However, this is not always practical. For example, recent neural networks such as XLNet or GPT-3 can take weeks to train and are very expensive. Additionally, for some applications, the full training set may no longer be available due to regulatory or privacy requirements. At Abacus.AI, we are designing new post-hoc methods, which take as input a pretrained model and a smaller validation dataset, and then debias the model through fine-tuning or post-processing. We have designed three new techniques which work for applications with tabular data or structured data. See our blog post for more information.
In addition to bias, we are actively working on explainability in neural networks. Business Analysts and subject matter experts within organizations are often frustrated when dealing with deep learning models. These models can appear to be black boxes that generate predictions which humans can't explain. Over the last two years, there has been considerable research in explainability in AI. This has resulted in the release of an open-source tool, LIME, which measures the responsiveness of a model's outputs to perturbations in its inputs. Then there's SHAP (SHapley Additive exPlanations), a game-theoretic approach to explain the output of any machine learning model. Google has introduced Testing with Concept Activation Vectors (TCAV), a technique that may be used to generate insights and hypotheses. Google Brain's scientists also explored attribution of predictions to input features in their 2016 paper, Axiomatic attribution for deep neural networks. Our efforts in this area build on these techniques to create a cloud microservice that will explain model predictions and determine if models exhibit bias.






























 Forecasting and Planning
Forecasting and Planning
 Marketing and Sales AI
Marketing and Sales AI
 Anomaly Detection
Anomaly Detection
 AI Foundation Models
AI Foundation Models
 Language AI
Language AI
 Fraud and Security
Fraud and Security
 Enterprise Gen AI
Enterprise Gen AI

 Structured ML
Structured ML
 Vision AI
Vision AI

 AI Personalization & Recommendation Engine
AI Personalization & Recommendation Engine